|
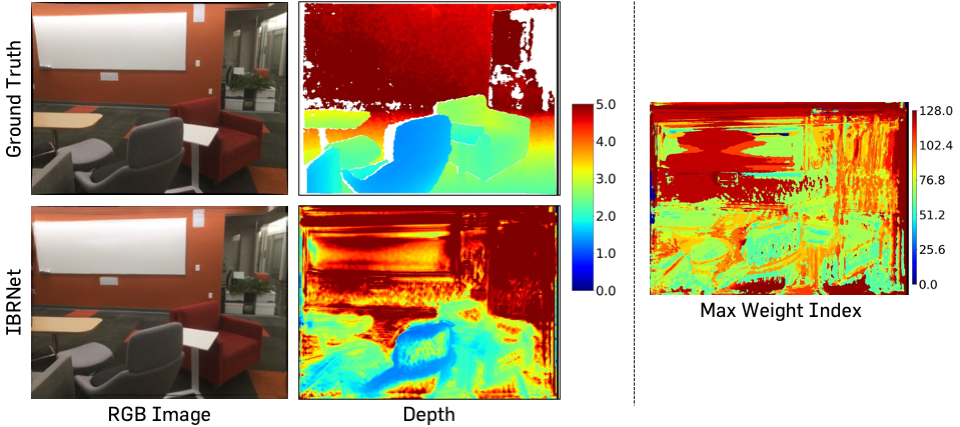
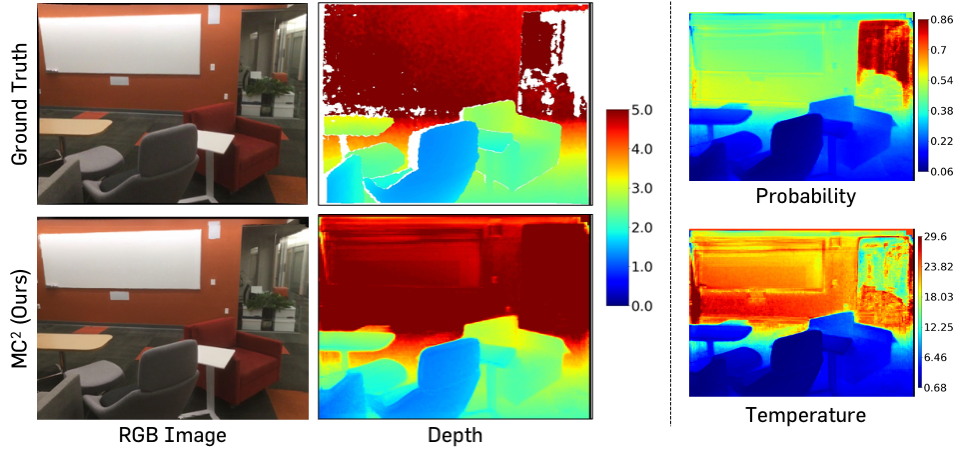
Illustration of depth estimates and corresponding synthesized RGB images
from IBRNet.
The color bar on the right side of the depth maps indicates the depth scale in meters.
Additionally, the index value with the largest predicted density weight
from IBRNet is shown (right),
and the color bar indicates the sample index in the range of 0 to 127.
As shown in above figure, IBRNet
typically assigns the highest weight to the last index in the
sample along the ray.
This phenomenon occurs primarily
when IBRNet struggles to identify correspondences
between context features derived solely
from image encoders, especially in textureless regions (e.g., walls, flat surfaces).
We conjecture that this happens because IBRNet's
primary focus is on plausible view synthesis
rather than accurate depth estimation.
Such a bias manifests itself in the following ways: objects that are predicted to be farther
away and thus to have greater depth tend to show only small pixel shifts across different
viewpoints, even with significant changes in camera perspective; on the other hand, objects that
are perceived to be closer show pronounced pixel movement within the images, even with minimal
changes in camera angle. Thus, when optimizing image-based neural rendering networks for color
image synthesis, there is a strong bias toward synthesizing images in which the relative motion
of objects matches their expected real-world behavior.
This prioritizes visual realism at the expense of accurate depth estimation,
especially in the absence of explicit geometric modeling such as image-based view synthesis.
|